The remarkable capabilities and open-source availability of DeepSeek-R1, created by the Chinese AI startup DeepSeek, have caused quite a stir in the AI community. This model's performance is drawing attention due to its innovative architecture, cost-efficient design, and the fact that it rivals top models from OpenAI. Recently, DeepSeek-R1 has been recognized for its efficiency gains, being up to 50 times cheaper to run than many U.S. AI models, which has significant implications for the global AI race.
A number of organizations have deployed DeepSeek-R1 with the help of Indian Python developers. The model's open-source nature allows developers to freely access, customize, and deploy locally, further enhancing its appeal. Newer versions of the model, such as R1 1776, try to improve its ability to answer any question objectively and factually.
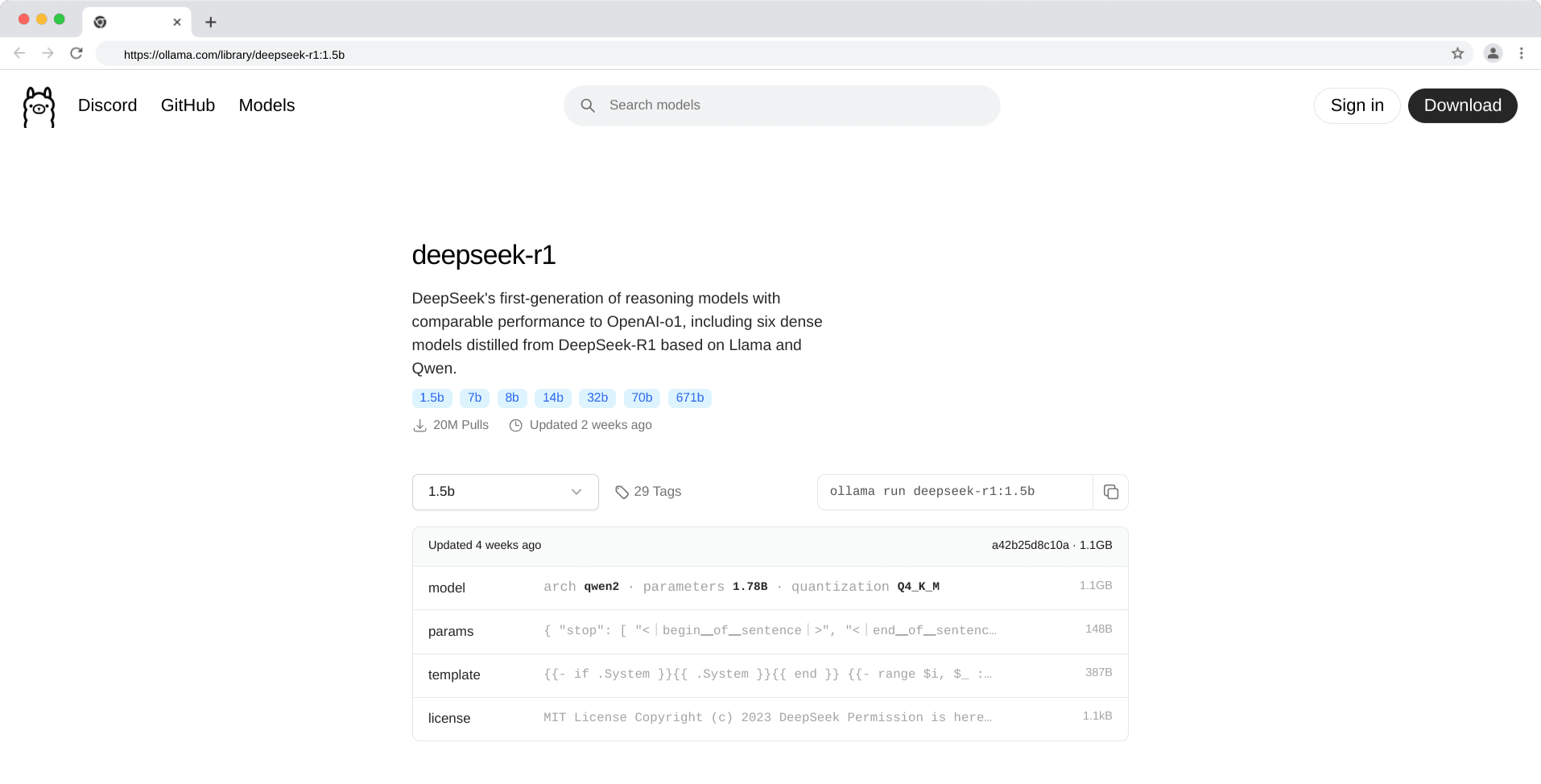
Here in this blog, we'll go over the basics of installing DeepSeek-R1 on your machine with Ollama, and then we'll delve into its usage and potential in artificial intelligence development.